Web Page Scraping funciona na página atual: abra o painel, clique nos elementos para criar colunas e exporte a tabela em CSV.
Passo 1: Instale e abra uma página compatível
Instale o Web Page Scraping e abra a página desejada. A extensão roda apenas em páginas http(s) comuns e rende melhor com layouts repetidos (cartões, linhas, itens de lista).
Passo 2: Abra o painel
Clique no ícone da extensão na barra de ferramentas. Um painel flutuante aparece no canto inferior direito com Columns e Table.![]()
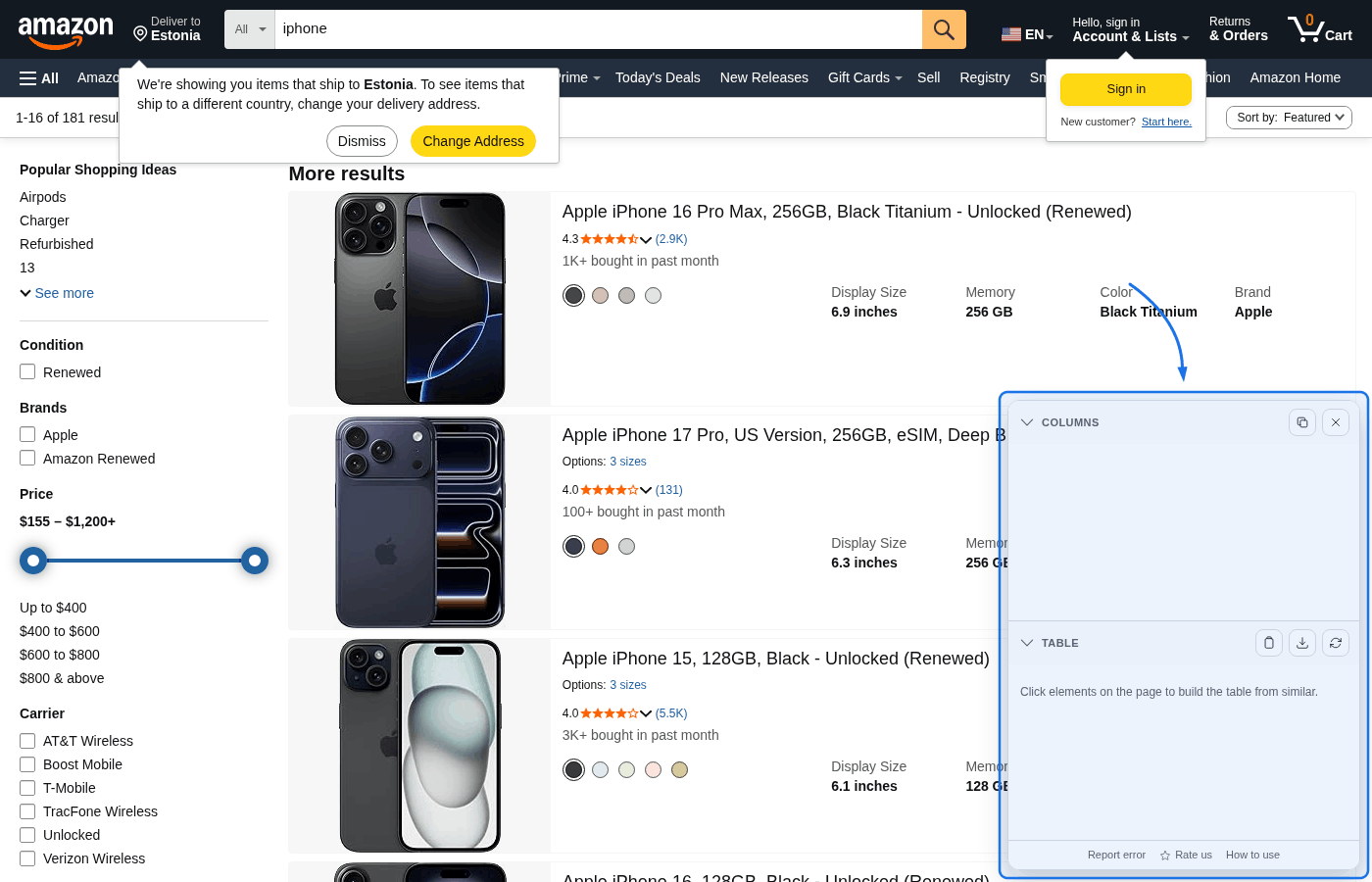
Passo 3: Escolha colunas clicando nos elementos
Clique em um elemento (título, preço, avaliação etc.). Elementos semelhantes são destacados e viram uma coluna. Repita para cada campo desejado.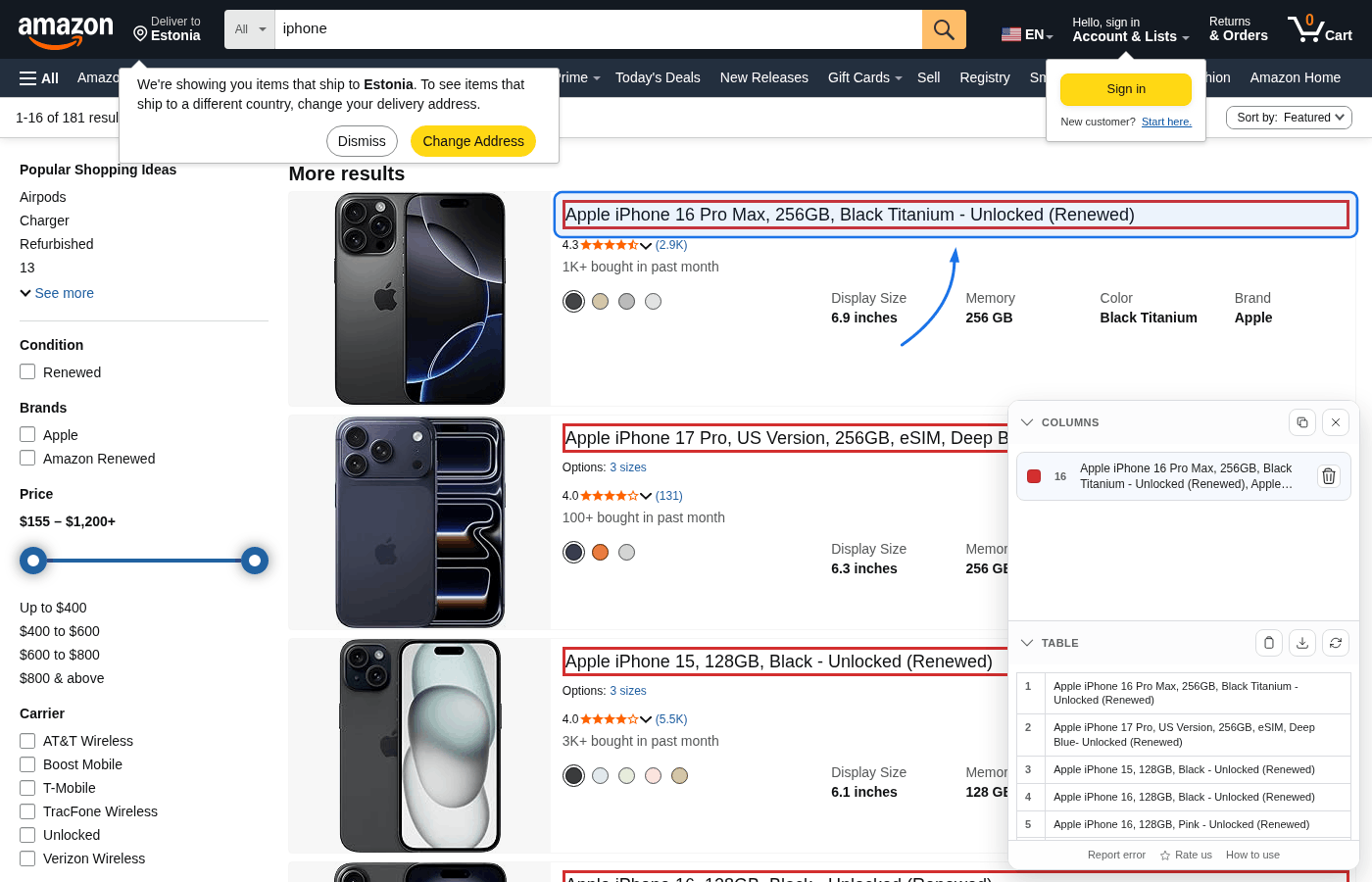
Passo 4: Ajuste e atualize quando precisar
Você pode remover uma coluna da lista Columns, usar o botão direito no destaque ou clicar de novo no elemento.
Refresh table é importante quando a página cresce depois da primeira montagem – por exemplo, scroll infinito ou “carregar mais”. Esses itens novos não estavam no DOM quando você definiu as colunas. Role/carregue o conteúdo e clique em Refresh table para que a prévia e o CSV batam com a página.
O mesmo vale se blocos carregados trocam o conteúdo: atualizar relê o DOM ao vivo.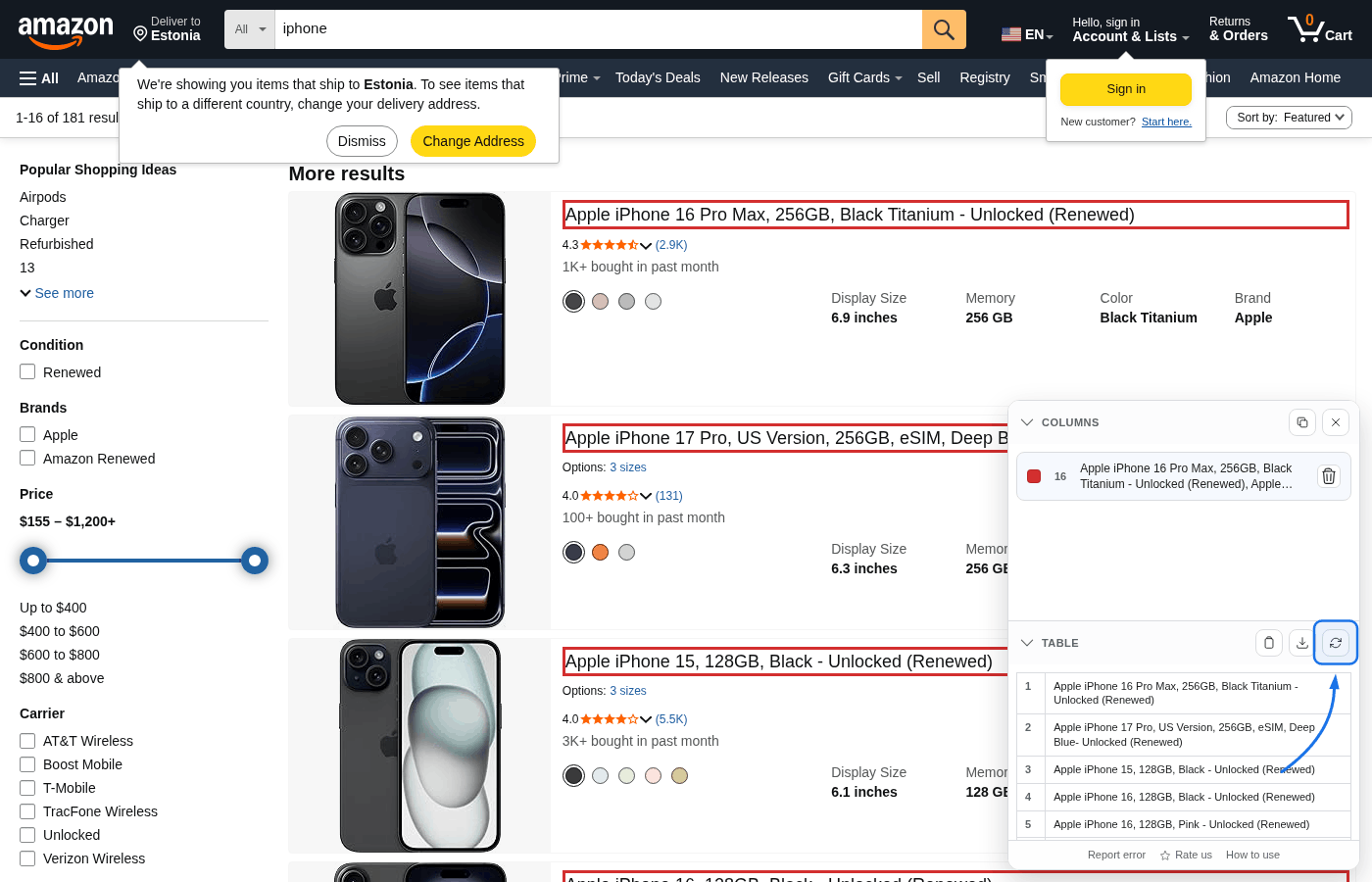
Passo 5: Exporte CSV
Revise as linhas em Table e exporte com Copy CSV ou Save CSV. O nome padrão é table-results.csv.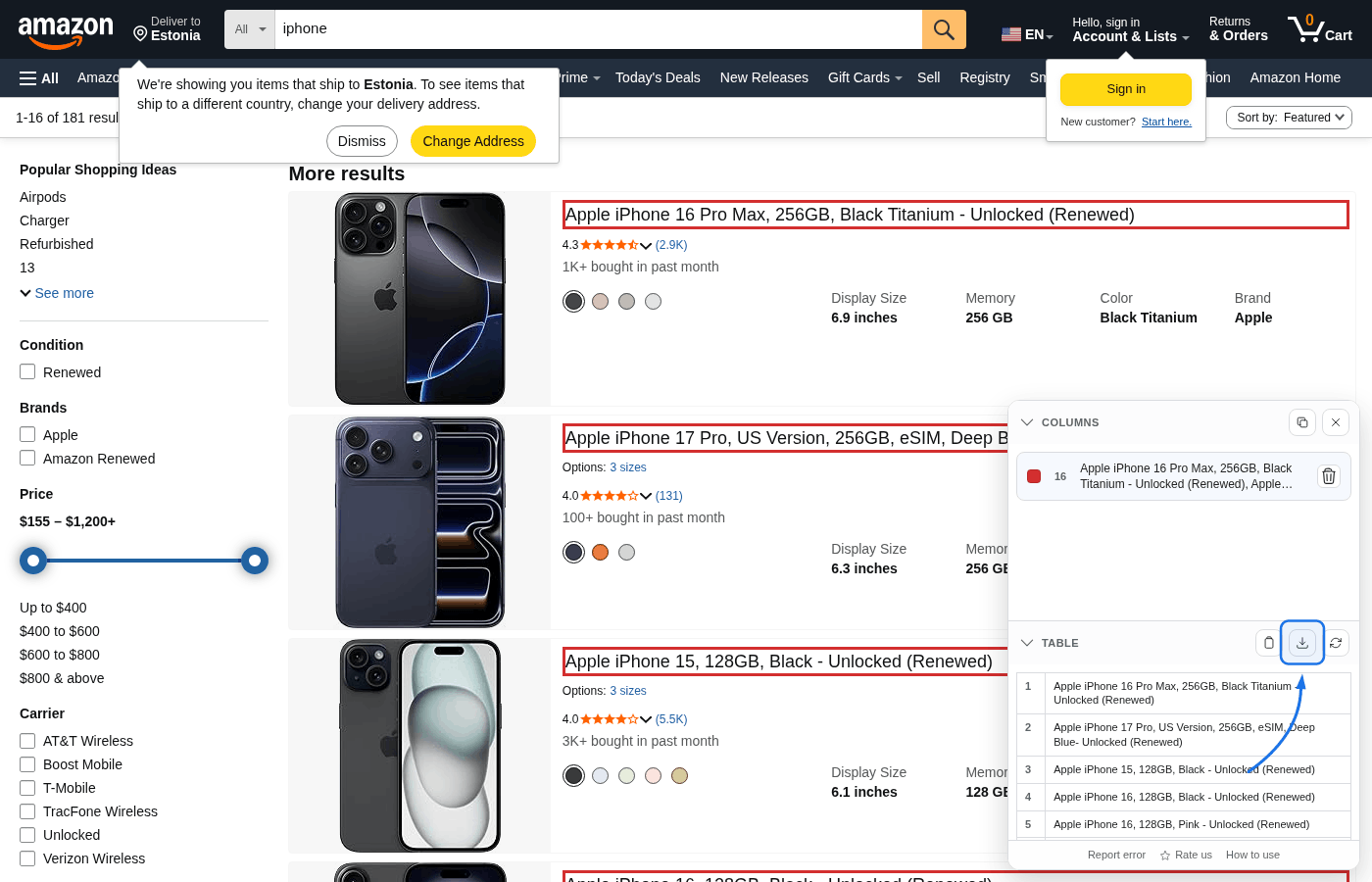
O que o algoritmo faz
O fluxo é guiado por você; correspondência estrutural monta as linhas:
- A primeira seleção bem-sucedida define uma “impressão digital” do contêiner repetido.
- Cada clique seguinte vira uma relação estrutural do contêiner ao alvo.
- Essa relação se repete nos contêiners compatíveis para preencher a coluna.
- Table alinha colunas pela ordem do DOM.
- O CSV reflete o DOM atual; atualizar sincroniza o conteúdo.
Dicas para bons resultados
- Finanças e notícias jurídicas: manchete, trecho e link da fonte.
- Resultados de busca: título, URL e snippet em colunas separadas.
- Produtos: título e preço primeiro; depois avaliação/contagem opcional.
- Sem correspondência útil? Escolha um elemento mais específico dentro de um cartão/linha repetida.
Limitações
Só http(s): sem painel em páginas internas do Chrome, páginas de extensão ou Chrome Web Store.
Página atual: sem paginação ou scroll automático – carregue os dados e atualize a tabela.
Células de texto: CSV a partir de elementos correspondentes; mídia binária não entra no arquivo.
Sem iframes: conteúdo dentro de iframes não é capturado.
Solução de problemas
- Painel não abre: confirme URL com
http://ouhttps://. - Destaque errado: clique em um nó mais profundo dentro do item repetido.
- Tabela desatualizada: use Refresh table após lazy-load.
- Suporte: Report error no rodapé do painel para relatório estruturado.
Roteiro
Pretendemos oferecer exportação JSON, uma API e integração MCP (Model Context Protocol) para bots e LLMs locais solicitarem dados estruturados sem passos manuais.